长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的 RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的 RNN 都具有一种重复神经网络模块的链式形式。在标准 RNN 中,这个重复的结构模块只有一个非常简单的结构,例如一个 tanh 层。
什么是RNN
RNN 和 LSTM 都是用于时序数据预测的网络结构,两者都可以说是用一个个的单元(unit)拼接而成

每一个单元中会配有激活函数来为模型引入非线性性质。由于是时序数据,例如每一分钟卫星会给你发回来一份观测数据,你的输入也是按照时间排列的。图中的RNN的每个单元会输出两个值,一个称为隐藏值(向右的箭头),而这个隐藏值也会作为下一个单元的输入。同时,下一个时刻(timestamp)也会作为新的输入。在图中这个模型中每个单元还会有预测输出,这就是为什么这个模型适合用于时序数据,因为它的结构使其可以根据之前的数据和新的输入结合起来进行预测。不过图中只是众多RNN的一种,它可以有很多层,或者只有一个输入或者输出。
输入时和预测时也像普通的神经网络一样会引用权重(Weights)和偏差(Bias)+ 激活函数的组合来处理,这些参数一般都是随机初始化的,也有一些其他更好的策略(但是我不懂),同时用 Back Propagation Through Time 来寻找让输出的损失最小的值。
LSTM的结构与原理
LSTM 最初由 Sepp Hochreiter 和 Jürgen Schmidhuber 于 1997 年提出。LSTM 旨在解决传统 RNN 在处理长序列数据时遇到的梯度消失或梯度爆炸问题,从而能够更好地学习长期依赖信息。简单的来说就是这个模型没有那么容易 “忘记” 之前的数据,例如一个月前的卫星数据我们称为 D_1, 而一个月后的数据是 D_1000, 这些都会在同一个训练周期输入,而普通 RNN 在处理到 D_1000 的时候可能就用不上 D_1 的数据了。
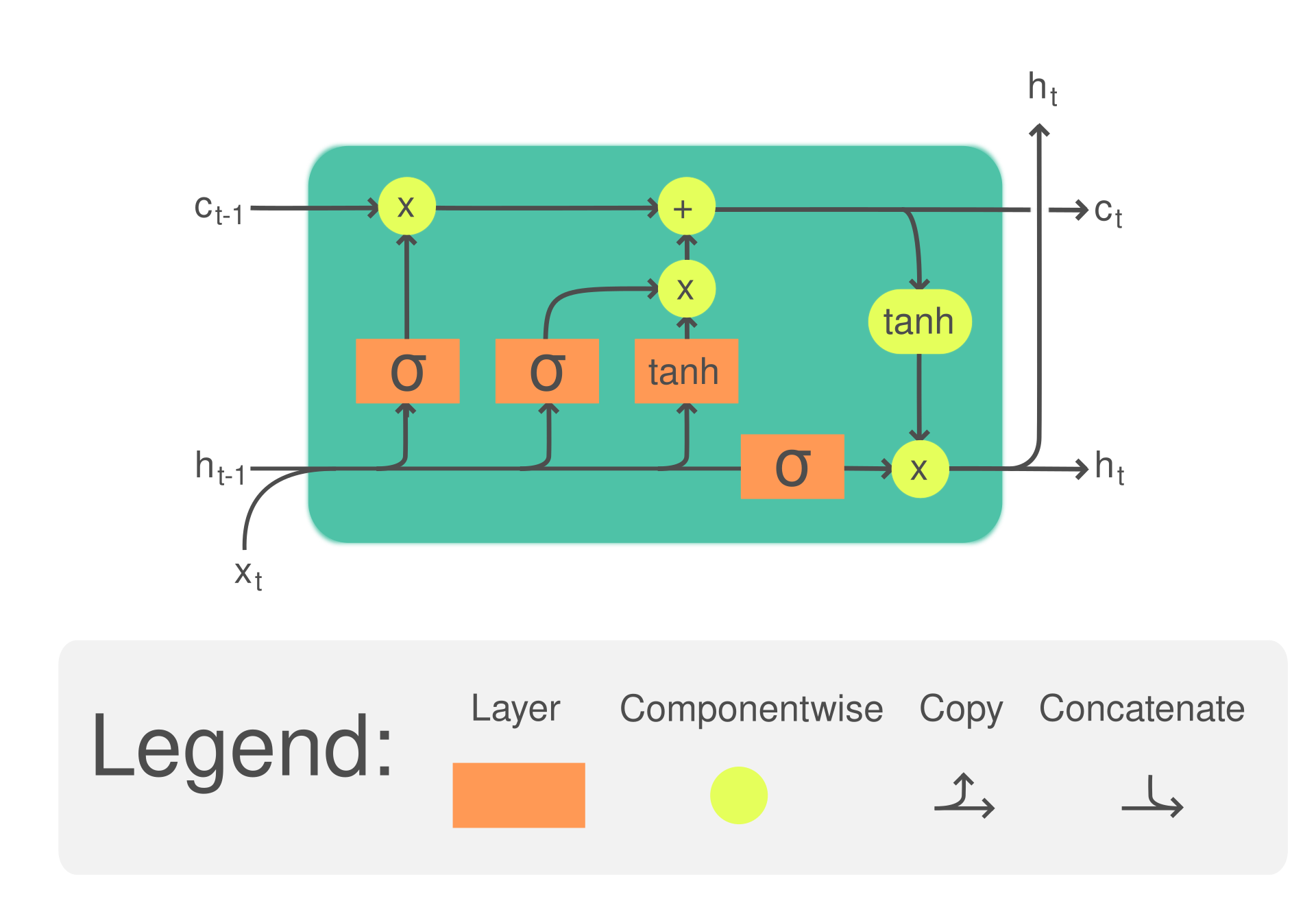
那么我们就来看看 LSTM 有什么神奇的结构吧。刚才我们提到 RNN 是由一个个单元组成的,LSTM 则是用一个个较为复杂的单元组成的,下面是这个结构的图片:

和刚才提到的普通的RNN单元相比高级了不少,其中输入和输出都变成了两个,此外还有一个output输出可用于预测。内部结构进行了一系列操作,让我们来慢慢拆解:

圆圈代表 Hadamard product (element-wise product)。
x,h,c 是输入向量(矩阵)。
W 代表 Weight,b 代表 Bias,此外还用到了两种激活函数:sigmoid 和 tanh。W 和输入之间的运算是 Dot Product。还有一些关于 LSTM 的 term:
- 单元状态 (Cᵗ):这代表 LSTM 的记忆,可以存储长序列信息。它可以在每个时间步骤中更新、清除或读取。 隐藏状态
- (Hᵗ):隐藏状态充当单元状态和外部世界之间的中介。它可以选择性地记住或忘记来自单元状态的信息并产生输出。 输入门
- (iᵗ):输入门控制信息流入单元状态。它可以学习接受或拒绝传入数据。 遗忘门
- (fᵗ):遗忘门确定应保留前一个单元状态的哪些信息以及应丢弃哪些信息。它允许 LSTM“忘记”不相关的信息。 输出门
- (oᵗ):输出门控制用于在每个时间步骤产生输出的信息。它决定应该向外部世界透露单元状态的哪一部分。
i\f\t 这三个 gate 的输入和计算都是相似的,我们只需要知道他们的 Weight 和 Bias 都是分开计算和优化的,因为他们的功能本身就不一样,BPTT 会帮助我们训练出这些权重来让模型最好的适应数据,最小化损失。
Ct 和 ht 的计算在这里就不多说,一系列操作就在公式中。
直观理解LSTM
我们可以将 ft 和 i_t 想象成更新记忆的权重,如果我们需要忘记,那么 ft * c_t-1 这一项就会变小,而 i_t 这一项就会变大,功能 ct 就实现了保留或者是更新的功能。
在 ot 的计算中我们用到了当前输入,上一个 h(短记忆 h_t-1),和当前更新后的 ct(当前记忆),所以 ht 在网络中一个一个单元传播下来总是倾向于保留短期的记忆(因为要及时表达出来)。
通过这些权重和激活函数的结构的搭建,Ct 就像是模型的长期记忆,ht 是短期,而我们就实现了长短期记忆的功能。
那么问题来了,为什么要这么搭建呢?为什么用这些激活函数和权重组合起来真就有用呢?为什么是这四个门控机制不是三个或者五个?请看 gpt4... 好吧我没问出来。论文懒得去读了,总之就是这样,嗯,它确实管用。
LSTM的变种ConvLSTM
我们刚才提到了 LSTM 在时序数据中预测的强大功能,那么这些数据能不能是图片呢?没有问题!在 2015 年的一篇文献 Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting 中,来自香港的作者提出我们可以将 LSTM 的输入变为图片并搭配卷积核(filter/kernel)来提取图片的特征,并且达成预测未来帧的功能。作者认为,如果是传统的 ROVER 模型(我不懂)或者是数值预报对于短临降雨的预测都没有能够结合其空间尺度的特性,我理解的意思就是只运用了数值,但是实际上也有在可视化了降雨强度之后能观察到的空间特征,比如云层遮挡等等,这些可以在雷达回波的雷达图中表达出来。下面是论文中的图片示例(这是一篇比较短的论文其中并没有太多对结构的详细描述):



为什么输入是三维的呢?因为是通过过去的帧来预测未来帧,我们就可以将这些帧堆叠在一起形成一个3D的输入。
通过数层的卷积层和LSTM单元的堆叠,我们就得到了这个新的网络。它分为提取部分和预测部分,预测部分也用到了LSTM单元,这一点和传统的串行LSTM稍有不同。
虽然文章不长,但就犹如 ResNet 对于深度学习,Transformer 对于语言模型,convLSTM 乃是短临预报(短期临近气象预报)和深度学习结合的开山之作之一。在此基础上还有它的升级版 TrajGRU(挖坑),之后看有没有心情填吧。
除此之外,convLSTM 算是视频预测的一种,
视频预测的应用还有
- 自动驾驶
在自动驾驶领域,视频预测技术可以帮助汽车预测周围环境的动态变化,比如其他车辆的运动、行人的行动路线等,从而提前做出决策,确保行驶安全。通过对前方路况视频序列的分析预测,自动驾驶系统可以更加智能地控制车辆,提高反应速度。 - 视频监控
在公共安全和视频监控领域,视频预测技术可用于提前识别潜在的安全威胁或异常事件,如人群突然奔跑可能预示着紧急状况的发生,从而使得相关部门能够及时响应。此类技术有望极大提高公共安全的保障水平。 - 体育分析
在体育赛事直播或回放中,视频预测技术可以帮助分析运动员的动作和比赛趋势,对未来的动作或比赛结果进行预测。例如,通过分析足球运动员和球的位置关系,预测球员的下一步动作或球门的射门概率。 - 医疗影像
在医学领域,视频预测技术可以用于动态医疗图像的分析,如对心脏的跳动进行长期跟踪和预测,帮助医生进行诊断。通过分析历史医疗视频数据,可以更好地预测疾病的发展趋势和治疗效果。 - 娱乐和媒体生成
在娱乐和内容生成领域,视频预测技术可以用于生成连贯的视频片段,为动画制作、电影后期制作、游戏开发等提供辅助。通过预测视频中的动作和场景变化,可以创造出新的视觉内容,增强用户体验。 - 交互式应用
在交互式应用如增强现实(AR)和虚拟现实(VR)中,视频预测技术能够提高用户体验的流畅度和实时性。例如,在虚拟现实游戏中,对玩家的动作进行实时预测,实现更加流畅和自然的交互效果。
除 convLSTM 之外,还有一些用于视频预测的模型(继续挖坑):
- 3D 卷积神经网络 (3D CNN)
3D CNN 在视频识别和预测领域很受欢迎,因为它可以直接在原始视频数据上应用,无需对帧进行预处理。3D CNN 通过对多个连续帧使用 3D 卷积核进行处理,能够同时学习视频的空间特征和时间特征。
- 双向递归卷积神经网络 (Bi-directional Convolutional LSTM, Bi-ConvLSTM)
Bi-ConvLSTM 是 ConvLSTM 的一个扩展,可以捕获视频数据中的前后文信息。通过在时间维度上同时进行正向和反向传播,Bi-ConvLSTM 能够更全面地理解视频内容,提高预测的准确性。
- 生成对抗网络 (Generative Adversarial Networks, GANs)
GANs 在视频预测和生成领域显示出了强大的能力。GAN 通常由两部分组成:生成器和判别器。生成器负责生成尽可能以假乱真的视频序列,而判别器的任务则是区分视频是真实的还是由生成器产生的。通过这种竞争机制,GAN 能生成高质量的视频预测结果。
- Transformer模型
Transformer 模型最初是为自然语言处理 (NLP) 领域设计的,但也被逐渐应用于视频预测任务中。Transformer 通过自注意力机制捕获长距离依赖信息,对于处理时间序列数据特别有效。在视频预测中,Transformer 可以更好地理解视频的整体上下文信息。
- 时空图卷积网络(Spatio-temporal Graph Convolutional Networks, ST-GCN)
ST-GCN 在处理视频中的时空数据时特别有效,特别是在人体姿态估计和行为分析中。通过将视频表示为图形,其中节点表示视频帧中的关键点,边表示节点之间的时空关系,ST-GCN 能够捕捉复杂的时空动态。
- 变分自编码器(Variational Autoencoders, VAEs)
VAEs 是一种生成式模型,适合于学习高维数据的潜在表示,包括视频数据。在视频预测中,VAE 可以用来生成未来可能出现的视频帧,通过学习和建模视频数据的深层次特征。
这里介绍的是一个相对不那么热门但又十分有研究价值的应用呢。下面是
两组雷达图的label和预测结果:



一些雷达图示例:





雷达数据转灰度图数据预处理 (原文):
First, transform the intensity values Z to gray-level pixels P by setting
P = (Z−min{Z}) / (max{Z}−min{Z})
and crop the radar maps in the central 330 × 330 region. After that, we apply the disk filter5 with radius 10 and resize the radar maps to 100 × 100. To reduce the noise caused by measuring instruments, we further remove the pixel values of some noisy regions which are determined by applying K-means clustering to the monthly pixel average. The weather radar data is recorded every 6 minutes, so there are 240 frames per day.
This work is licensed under CC BY-NC 4.0
Incredible! This blog looks just like my old one!
It's on a completely different topic but it has pretty much the same page layout and design.
Wonderful choice of colors!
膜拜大佬